Kubernetes Active Active Clusters and Application Fault Tolerance

From Monolith to Microservices
Having redundancy in application space is pretty common. We have all seen them for decades in different ways. Hardware, software layer 4, or layer 7, etc. All of them what they do they direct traffic based on a given decision-making rule to a destination. Being weighted round-robin, resource/load-based metrics, etc. All they do is reliably direct traffic to a healthy node in the destination.
In a very simple and basic view with VMs and data centers, if VMs fail the load balancer will direct loads to identical VMs, all nodes more or less can handle any of the incoming requests (ignoring stickiness, etc.) If one node disappears another one will take the burden, hopefully without causing a cascading failure. No matter what type, the load balancer will add and remove the nodes based on their health or other metrics, API calls from the pool and add them back. When there are active-active or active/standby data centers the whole switch can happen between data centers manually or automatically when one data center is down or operating at the limit of its capacity, etc.
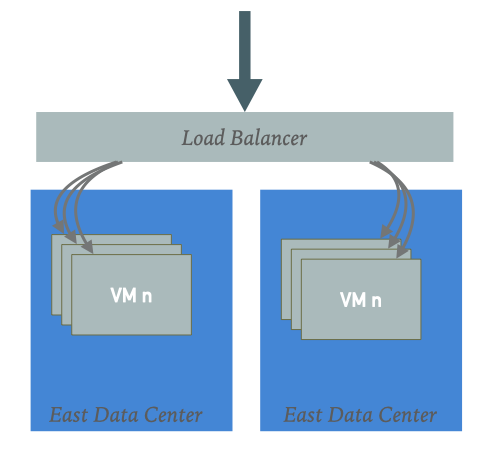
Microservices and redundancy
With Microservices it will change, as usually there is no single DNS name that can handle all the requests but somewhat different components of the system service different subsets of requests. Each of those monolith VMs is now several dozen separate services, being micro or mini. The microservices are usually deployed in a Kubernetes distribution, using namespaces for each service or group of services that can form a boundary. Services are redundant across clusters; usually, the clusters are identical replicas in sense of the service dependency graph.
Some of the services are serving requests that are originating from outside of the Kubernetes cluster, call them ** services and some of the services are only serving requests that originated from inside the cluster call them Core services. The experience services are load-balanced across the two clusters using hardware or software sitting outside these clusters. The Core services in each cluster serve the internal requests in that cluster.
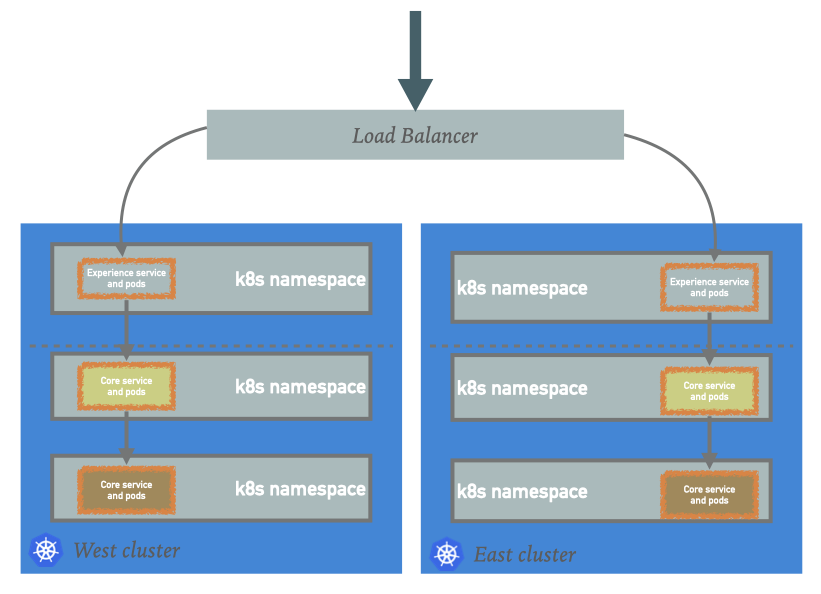
Services in each cluster have a health check, which includes their dependencies health check. The health check happens at intervals so an Experience service knows if the dependencies are healthy and it can operate or not, and it exposes that status as its own health check to the load balancer.
Microservices and cluster reliability
The problem arises when some of the Core services are not implementing the health check or that a Core service that handles a fraction of these requests that arrive at the experience service is dying off in one cluster. The health check cascade will put the experience service in that cluster out of the origin pool and route all the requests to another cluster. As image below first, the Core service fails then the health check cascade results in the load that was handled by the west is now routed to the east.
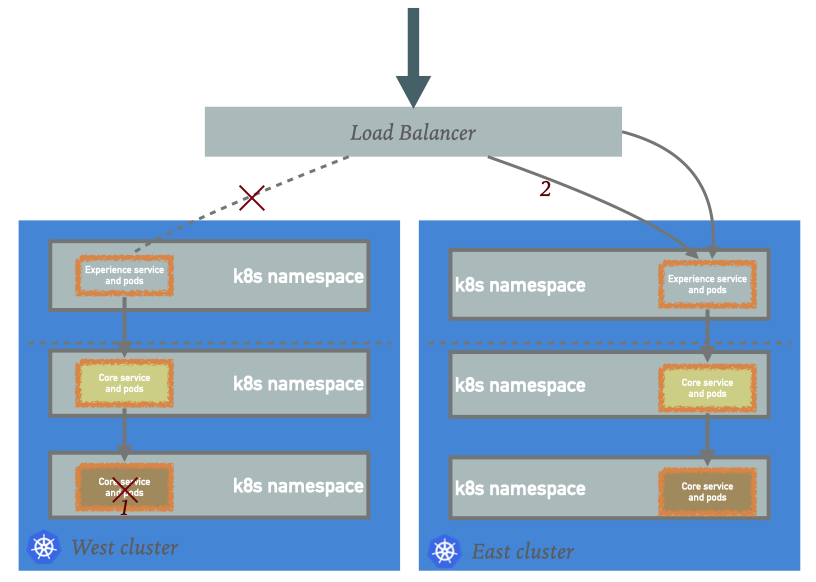
This other cluster either needs to autoscale to bear the load or have service degradation until the Core service is restored.
Some of the solutions for cross-cluster load balancing:
- Exposing every single service as using DNS. The load balancing happens outside the cluster as the load balancer, generally sitting outside the cluster. It is simple and well-known how to manage DNS records and load balancers in any big organization. The big disadvantage is the traffic routing cost (time and CPU) in and out of the clusters and the increased failure chance with the LB instance/s being the SPF.
- Using Skupper which provides a level 7 virtual application network (VAN) layered on top of the already existing network. Skupper uses Apache Qpid Router and performs cross-cluster load balancing among a few other things. It is simple and very lightweight to use. It needs no cluster administrative privileges to install and overall automation for a cross-cluster load balancing is pretty straightforward (plenty of examples in their website). On the flip side if skupper proxies a service, the applications cannot do network port negotiations for example. E.g. FTP. Skupper is a completely decentralized solution for cross-cluster load balancing. Each namespace owner can decide to use it or not.
- Use a Service Mesh federation. Service mesh is a component that can help with addressing quite an array of requirements, one being cross-cluster load balancing! The mesh can dynamically balance the load between the two clusters for any of the service constructs that are enrolled. The disadvantage is the complexity of the service mesh operation and management. Of course, the mesh provides many other functionalities which if the organization requires it may be a reasonable solution. Depending on the organizational setup and cluster access levels a service mesh can be a semi-centralized solution. CRDs are managed by namespace owners and overall operation by cluster admins
- Using Submariner that manages the network mesh in layer 3. If the clusters are already set this is going to be difficult to roll out. It needs cluster-admin access as well as the complexity of maintenance and management. Dealing with compatibility between different cluster versions/flavors may also become an extra maintenance cost. The solution is centralized and managed by cluster admins.
All of these solutions:
- Provide a control plane
- Full host of monitoring capacity (from having their own console and GUI to exposing a Prometheus scrapable endpoint)
- Support, e.g. from a vendor like redhat
- Cross cluster load balancing and routing
- Provide encryption for the communication channel
The solutions differ on:
- What other functionalities do they provide
- What level of complexities do they impose on the infrastructure
- what network layer implications do they have
- What level of complexities are exposed to application developers
Which way to go depends on the context and the expected outcome(s). If none of the functionalities listed for Submariner and Istio are needed then something like Skupper is the definite answer. If the organization requires more QoS that are provided by e.g. Istio or LinkerD then the service mesh is the way to go. But generally speaking, using the simplest solution with a bit of thought about how will it scale in the future should be the first MVP and attempt in addressing a requirement.